线程同步
为什么做同步
多个线程访问共享资源时,必须要一个一个来,特别是对于写操作来说,边读边写也是危险的。
// 功能:两个函数同时数数,对number修改,每个线程数5次,期望最终得到10
#include <iostream>
#include <thread>
#include <unistd.h>
int MAX(5);
int number = 0;
void funcA_num() {
int cur;
for (int i = 0; i < MAX; ++i) {
cur = number;
cur++;
usleep(5);
number = cur;
std::cout << "Thread A, id = " << std::this_thread::get_id() << " number = " << number << std::endl;
}
}
void funcB_num() {
int cur;
for (int i = 0; i < MAX; ++i) {
cur = number;
cur++;
usleep(3);
number = cur;
std::cout << "Thread B, id = " << std::this_thread::get_id() << " number = " << number << std::endl;
}
}
int main() {
std::thread t1(funcA_num);
std::thread t2(funcB_num);
t1.join();
t2.join();
}
/*
Thread B, id = 0x16b56f000 number = 1
Thread A, id = 0x16b4e3000 number = 1
Thread B, id = 0x16b56f000 number = 2
Thread A, id = 0x16b4e3000 number = 2
Thread B, id = 0x16b56f000 number = 3
Thread B, id = 0x16b56f000 number = 4
Thread A, id = 0x16b4e3000 number = 3
Thread B, id = 0x16b56f000 number = 5
Thread A, id = 0x16b4e3000 number = 6
Thread A, id = 0x16b4e3000 number = 7
*/ // 为什么不是10?
解释:
由于引入了缓存,所以举个例子:
- A抢到时间片数了3次,其中1、2都写回到了内存,但是3没来得及写回去,保存在了寄存器当中
- 此时B抢到了时间片,他读取到内存中是2,从2开始数,导致错误❌,假设数到了6,但只有5已经存回到了内存
- 那么此时A从5开始数。
因此会有重复数数的问题。由此我们必须引入线程同步
同步的方式有四种
- 互斥锁
- 读写锁
- 条件变量
- 信号量
线程同步方法1–互斥锁[^1.2.4^](#1)
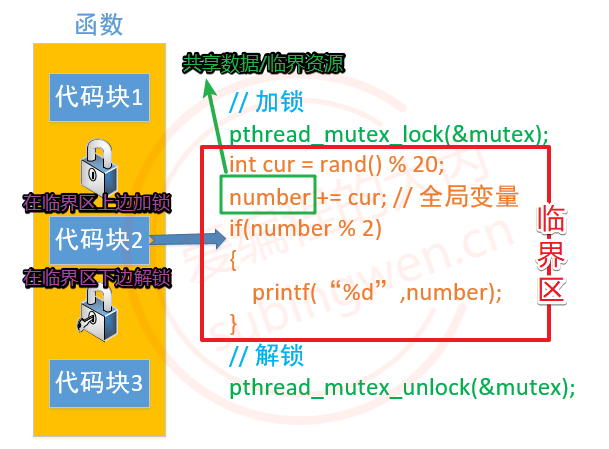
共享资源也被称为临界资源
如何算临界区:如下图,number作为共享资源,一切==和它有关==以及==和它的有关有关==以及==更深层的有关==的代码都算在临界区内(株连九族)。
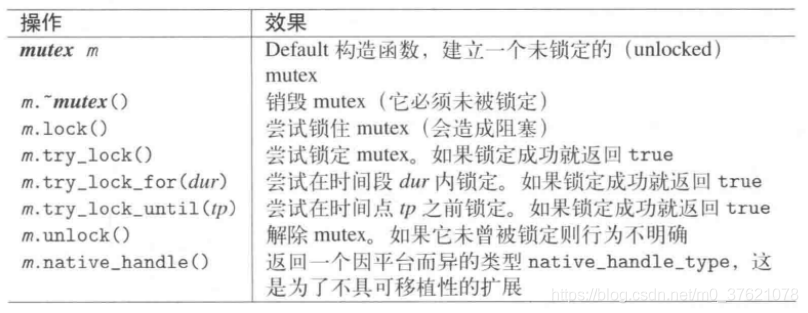
重要函数原型
#include <mutex>
class mutex {
public:
constexpr mutex() = default;
mutex(const mutex&) = delete;
mutex& operator=(const mutex&) = delete;
}
使用类来管理资源–lock_guard、unique_lock


| 类模板 | 描述 | 策略 |
|---|---|---|
| std::lock_guard | 严格基于作用域(scope-based)的锁管理类==模板==,构造时是否加锁是可选的(不加锁时假定当前线程已经获得锁的所有权—使用std::adopt_lock策略),析构时自动释放锁,所有权不可转移,==对象生存期内不允许手动加锁和释放锁== | std::adopt_lock |
| std::unique_lock | 更加灵活的锁管理类==模板==,构造时是否加锁是可选的,在对象析构时如果持有锁会自动释放锁,所有权可以转移。对象生命期内允许手动加锁和释放锁 | std::adopt_lock std::defer_lock std::try_to_lock |
样例
// 升级前面的数数的多线程代码
#include <iostream>
#include <thread>
#include <unistd.h>
#include <mutex>
std::mutex lock_;
int MAX(5);
int number = 0;
void funcA_num() {
int cur;
for (int i = 0; i < MAX; ++i) {
{
std::lock_guard<std::mutex> lg(lock_);
cur = number;
cur++;
number = cur;
std::cout << "Thread A, id = " << std::this_thread::get_id() << " number = " << number << std::endl;
}
usleep(3); // 加上这个不要让某个线程总是抢到时间片,
// 主要是为了后续打印的结果可以看出来是随机抢时间片的,确实是并行的
}
}
void funcB_num() {
int cur;
for (int i = 0; i < MAX; ++i) {
{
std::lock_guard<std::mutex> lg(lock_);
cur = number;
cur++;
number = cur;
std::cout << "Thread B, id = " << std::this_thread::get_id() << " number = " << number << std::endl;
}
usleep(5);
}
}
int main() {
std::thread t1(funcA_num);
std::thread t2(funcB_num);
t1.join();
t2.join();
}
/*
Thread B, id = 0x16fe47000 number = 1
Thread A, id = 0x16fdbb000 number = 2
Thread B, id = 0x16fe47000 number = 3
Thread A, id = 0x16fdbb000 number = 4
Thread B, id = 0x16fe47000 number = 5
Thread B, id = 0x16fe47000 number = 6
Thread A, id = 0x16fdbb000 number = 7
Thread A, id = 0x16fdbb000 number = 8
Thread B, id = 0x16fe47000 number = 9
Thread A, id = 0x16fdbb000 number = 10
*/
// 本例适合用 lock_guard 是因为刚好临界区是一整个代码块,在这个代码块中新建 lock_guard 类
// 退出代码块后自然就调用lock_guard 的析构函数进行解锁
死锁
锁的个数 = 共享资源的个数 != 线程的个数
- 重复加锁
- A拿着X的钥匙想访问Y,B拿着Y的钥匙想访问X。即A拿着X房间的钥匙但被锁在Y房间,B拿着Y房间的钥匙却被锁在了X房间。
线程同步方法2–读写锁[^4.5.6.7^](#2)
头文件为 shared_mutex。c++14通过 shared_timed_mutex 提供读写锁,c++17通过 shared_mutex 提供读写锁
拥有两个访问级别:
- 共享–多个线程能共享同一互斥的所有权
- 独占性–仅一个线程能占有互斥
读写锁优点:可以同时读,即读操作是可以并行的。但是写操作还是串行的
| 当前锁的状态 | 读锁请求 | 写锁请求 |
|---|---|---|
| 无锁 | 可以 | 可以 |
| 读锁 | 可以 | 阻塞 |
| 写锁 | 阻塞 | 阻塞 |
重要函数原型
class shared_timed_mutex{
shared_timed_mutex();
~shared_timed_mutex() = default;
shared_timed_mutex(const shared_timed_mutex&) = delete;
shared_timed_mutex& operator=(const shared_timed_mutex&) = delete;
}
使用类来管理资源–shared_lock、unique_lock
- shared_lock 是==共享==互斥所有权包装器
- unique_lock 是==独占==互斥所有权包装器
样例
// 5个读线程,3个写线程 操作同一个全局变量
#include <iostream>
#include <thread>
#include <unistd.h>
#include <shared_mutex>
#include <vector>
std::shared_timed_mutex sLock;
int number = 0;
const int MAX(3);
void read_num() {
int cur;
for (int i = 0; i < MAX; ++i) {
{
std::shared_lock<std::shared_timed_mutex> slk(sLock); // 使用 shared_lock 管理锁,自动解锁并且不阻塞读线程
std::cout << "Thread read, id = " << std::this_thread::get_id() << " number = " << number << std::endl; // 临界区只有这一行
}
usleep(rand()%5);
}
}
void write_num() {
for (int i = 0; i < MAX; ++i) {
{
std::unique_lock<std::shared_timed_mutex> ulk(sLock); // 使用 unique_lock 管理锁,自动解锁并且阻塞其他读写线程
number++;
std::cout << "Thread write, id = " << std::this_thread::get_id() << " number = " << number << std::endl; // 临界区只有这一行
}
usleep(rand()%5);
}
}
int main() {
std::vector<std::thread> read_t(5);
std::vector<std::thread> write_t(3);
for (int i = 0; i < 5; ++i) {
read_t[i] = std::thread (read_num);
}
for (int i = 0; i < 3; ++i) {
write_t[i] = std::thread (write_num);
}
for(int i = 0; i < 5; ++i) {
read_t[i].join();
}
for (int i = 0; i < 3; ++i) {
write_t[i].join();
}
return 0;
}
/*
Thread read, id = 0x16b4e7000 number = 0
Thread read, id = 0x16b68b000 number = 0
Thread read, id = 0x16b4e7000 number = Thread read, id = 0x16b717000 number = 0
0
Thread read, id = Thread read, id = 0x16b5ff0000x16b573000 number = number = 00
Thread write, id = 0x16b7a3000 number = 1
Thread write, id = 0x16b8bb000 number = 2
Thread read, id = 0x16b4e7000 number = 2
Thread read, id = Thread read, id = 0x16b573000 number = 20x16b5ff000 number = 2
Thread read, id = 0x16b68b000 number = 2
Thread write, id = 0x16b82f000 number = 3
Thread write, id = 0x16b7a3000 number = 4
Thread write, id = 0x16b82f000 number = 5
Thread write, id = 0x16b8bb000 number = 6
Thread read, id = 0x16b68b000 number = 6
Thread write, id = 0x16b7a3000 number = 7
Thread read, id = 0x16b5ff000 number = 7
Thread read, id = 0x16b573000 number = 7
Thread write, id = 0x16b82f000 number = 8
Thread read, id = 0x16b717000 number = 8
Thread write, id = 0x16b8bb000 number = 9
Thread read, id = 0x16b717000 number = 9
*/
// 从结果可以看出
// read 时输出会有错乱的情况,说明他们是并行的
// write 时的输出必定是独占一行的,说明 write_num 的线程是独占的,会将其他的线程阻塞
// 并且3个写线程每一个对 number 递增3次,最终得到 number = 9
线程同步方法3–条件变量[^4.8.9^](#3)
考虑==单生产者-单消费者==模型
按照上面两个同步技术:
- 生产者抢到时间片,写一个双端队列后,解锁。恢复就绪状态
- 此时生产者和消费者都处于就绪状态,共同抢时间片,假设消费者抢到了,发现队列有一个数据,然后消费掉。放弃cpu,恢复就绪态
- 此后假设一直是消费者抢到了时间片,那么就一直在做无用功(加锁-判断为空-解锁恢复就绪态)
出现此现象的根本原因在于生产者和消费者之间没有通信机制,造成盲目的抢时间片。因此通过条件变量来使它们可以通信。
条件变量是线程的另外一种有效同步机制。这些同步对象为线程提供了==交互==的场所(一个线程给==另外==的一个或者多个线程发送消息),我们指定在条件变量这个地方发生。==一个线程==用于修改这个条件变量使其满足其它线程继续往下执行的条件,==其它线程(可以是多个)==则等待接收条件变量已经发生改变的信号。当条件变量同互斥锁一起使用时,条件变量允许线程以一种无竞争的方式等待任意条件的发生。
重要函数原型
#include <condition_variable>
class condition_variable {
public:
constexpr condition_variable() noexcept = default;
condition_variable(const condition_variable&) = delete;
condition_variable& operator=(const condition_variable&) = delete;
void notify_one() noexcept;
void notify_all() noexcept;
void wait(unique_lock<mutex>& __lk) noexcept;
}

使用类来管理资源–unique_lock
一般只会使用 unique_lock。因为条件变量的锁的控制比较灵活,而 lock_guard 没有提供 lock()、unlok() 等接口,shared_lock 根本不是这个情形下使用的东西。
样例
// 5个生产者和5个消费者共同读写一个双端队列,队列最大长度为10
#include <iostream>
#include <thread>
#include <unistd.h>
#include <mutex>
#include <condition_variable>
#include <deque>
#include <vector>
std::condition_variable cond_empty;
std::condition_variable cond_full;
std::mutex lock_;
std::deque<int> q;
const int MAX_SIZE = 10;
void prod_fun() {
int number;
while(1) {
number = rand() % 10;
std::unique_lock<std::mutex> ulk(lock_);
while(q.size() == MAX_SIZE) { // 使用while而不是if的理由见后面的while语句块
cond_full.wait(ulk); // 拿到锁后若队列是满的,通过条件变量wait方法释放锁,进入休眠状态等待唤醒
}
q.push_back(number);
std::cout << "Thread producer, id: " << std::this_thread::get_id() << " insert " << number << std::endl;
ulk.unlock(); // 因为需要灵活 unlock,所以只能使用 unique_lock,而不能使用 lock_guard
cond_empty.notify_all(); // 唤醒消费者,可以开始消费了。另ps:这一行可以和上一行换行,不影响
sleep(rand()%2);
}
}
void cons_fun() {
int number;
while(1) {
std::unique_lock<std::mutex> ulk(lock_);
while (q.empty()) { // 使用while而不能是if:因为被唤醒后可能队列先被先前抢到时间片的消 // 费者消费完了,此时若不再次判断,直接往下执行,
// 就会发现 q 中没有资源而报错
cond_empty.wait(ulk); // 释放已经锁上的lock_,若释放后其他消费者抢到了,也都会被堵在这
// 只有被生产者抢到了,生产了资源,才能够继续往下执行
}
number = q[0];
q.pop_front();
std::cout << "Thread consumer, id: " << std::this_thread::get_id() << " delete " << number << std::endl;
ulk.unlock();
cond_full.notify_all(); // 唤醒所有的生产者可以开始生产了,因为消费了一个,自然就有空位了
sleep(rand()%2);
}
}
int main() {
std::vector<std::thread> producer(5);
std::vector<std::thread> consumer(3);
for (int i = 0; i < 5; ++i) {
producer[i] = std::thread (prod_fun);
consumer[i] = std::thread (cons_fun);
}
for(int i = 0; i < 5; ++i) {
producer[i].join();
consumer[i].join();
}
return 0;
}
/*
Thread producer, id: 0x16db77000 insert 7
Thread producer, id: 0x16dda7000 insert 8
Thread consumer, id: 0x16dc03000 delete 7
Thread producer, id: 0x16dda7000 insert 2
Thread consumer, id: 0x16dc03000 delete 8
Thread consumer, id: 0x16de33000 delete 2
Thread producer, id: 0x16dc8f000 insert 9
Thread producer, id: 0x16dfd7000 insert 2
Thread consumer, id: 0x16de33000 delete 9
Thread consumer, id: 0x16e063000 delete 2
Thread producer, id: 0x16dfd7000 insert 7
Thread producer, id: 0x16debf000 insert 9
Thread consumer, id: 0x16dd1b000 delete 7
*/
线程同步方法4–信号量[^10.11^](#4)
c++20 才开始支持信号量,先不进行了解了。之后有需要可以看参考资料 10.11 进行完善。